Dantotsu radical quality at AutoRABIT
The CodeScan team achieved 0 bugs with the Dantotsu "Better than the Best" approach. Their lead Vaibhav tells the story.

We have done it! The CodeScan development team at AutoRABIT went from an average of five new client bugs per week to zero in the last two weeks. Kudos to the team!
Betting on quality to scale
CodeScan is a static code analysis tool for Salesforce developed by AutoRABIT. It analyzes Apex code (a Java-like language with built-in DSL for database queries, and is proprietary to Salesforce), front-end web code, and Salesforce metadata. It detects potential bugs, configuration issues, and security issues both in code (e.g. SQL injection) and configuration (e.g. improper access rights). This product is becoming critical to most enterprises that use Salesforce. Salesforce boasts first place with 23% of market shares on the CRM market. In 2022, 11 million developers work on the Salesforce platform. Like it or not, Salesforce matters. A lot.
Salesforce developers are busy. They build critical software for many industries, including highly regulated ones like healthcare and banking. However, Salesforce is a proprietary platform. As a consequence, today’s classic DevSecOps tools don’t apply to it, which is why dedicated products like CodeScan exist. CodeScan is AutoRABIT’s new flagship product and has an opportunity to grab a big chunk of the market. But in order for this to happen, we need to make sure that our product is as robust as possible and can handle the growth, which was not the case only four months ago. For two simple reasons: we were spending too much time fixing avoidable problems, and bugs degraded the user experience. The first problem prevented us from delivering more value to customers fast, and the second problem prevented us from convincing existing and potential users to adopt our tool in the long run.
I was intrigued by the ideas of Dantotsu radical quality (Dantotsu means “Better than the Best” in Japanese). So I decided to give it a shot.
React vs reflect
“The analysis job randomly failed again”. The words appeared on my screen in the Zoho support ticket and were all too familiar. I sighed. This was yet another case of the "random analysis failures" bug. I knew the procedure to help my customer: first, open a ticket to the Service Reliability Operators team. Then wait until one of our engineers restarted the instance. When this is done, I need to follow up and tell our support team that the problem is fixed, and provide them with a Root Cause Analysis report. Then they would re-contact the customer, who would either find that our change has not worked (though this did not happen as much for this type of operation), or would not respond to us (in which case we’d close the ticket after a while).
This time was different though. I was sharing my screen with our Dantotsu coach, who got interested in this issue in detail.
“Does this happen often?” He asked.
“About once a week, but we made a change to fix it for good two weeks ago”, I said.
“Did the change work?”
“Well, yes, I think so.”
“So why is this issue coming up again?”
“It’s actually an old support ticket that was brought in before our change.”
“Can you show me recent analysis failures for this customer?”
“Ok let me pull them out for you.”
“If the change worked, why did a job fail yesterday?” He asked, looking puzzled.
“Hum, that’s strange… I don’t know.”
“Can we look at the logs?”
“Sure thing, let me also pull out the CloudWatch logs.”
We proceeded to understand the underlying issue together. We did not solve it that day but we found the mechanism that gripped. When the analysis run completes, it reports its result to a webhook. This webhook then informs the main backend that the job is done, and the user interface reflects this change. In our case, the HTTP call to the webhook never completed and failed with a silent DNS error. The DNS error was surprising, as we managed the entirety of the systems involved: the DNS records, load balancer, IP addresses, and servers are all hosted on AWS. We read about the DNS resolution mechanism and the way servers registered to an Application Load Balancer. In the end, we came up with six or seven cause hypotheses and with experiments to learn more about them. The idea was to do two things at the same time. First, reinforce the HTTP calls with retries. Second, gather more information about what was happening to not stop there and really understand what was happening.
To find the root cause of the issue we used a known problem solving technique called PDCA, which stands for Plan Do Check Act. I used to think I was doing PDCA when I was writing Root Cause Analyses to explain what went wrong. However, I quickly learned that I was doing this type of problem solving with the wrong spirit. My goal then was to react quickly and make changes fast. My coach taught me that PDCA really shines when used in a reflective fashion. The real goal is to solve problems with the pragmatism, curiosity, interest, and passion of a good scientist.
Starting from a customer problem, we first described it as a gap to a standard. Analysis jobs must only fail when the code has flaws–my customer’s analysis had failed even though their code was correct, that’s the gap. Then we deliberately moved through the evidence: logs, code, infrastructure configuration, or by talking with the people involved to find the contributing factors. We asked “why” five times to get to the root cause, in other words, the smallest mechanism that led to the error. We took the time to test different ideas along the way. In the scientific method, you start with a hypothesis, design an experiment, write what you expect will happen, run the experiment, check the result, and reflect on what you have learned. There are no failed experiments as long as you learn something along the way and you find out what you need to change in your work methods. PDCA emphasizes the Plan phase to prepare good experiments. Do and Check care about what happened during the experiment, and whether what we thought would really happen. Act is about leadership and sharing useful learnings across my team and other teams in the company.
After doing multiple PDCAs, I realized that the pinnacle of a good root cause was getting to a misconception, a basic principle that someone on the team thought was true but was wrong. And this became key to my team’s success.
The joy of quality
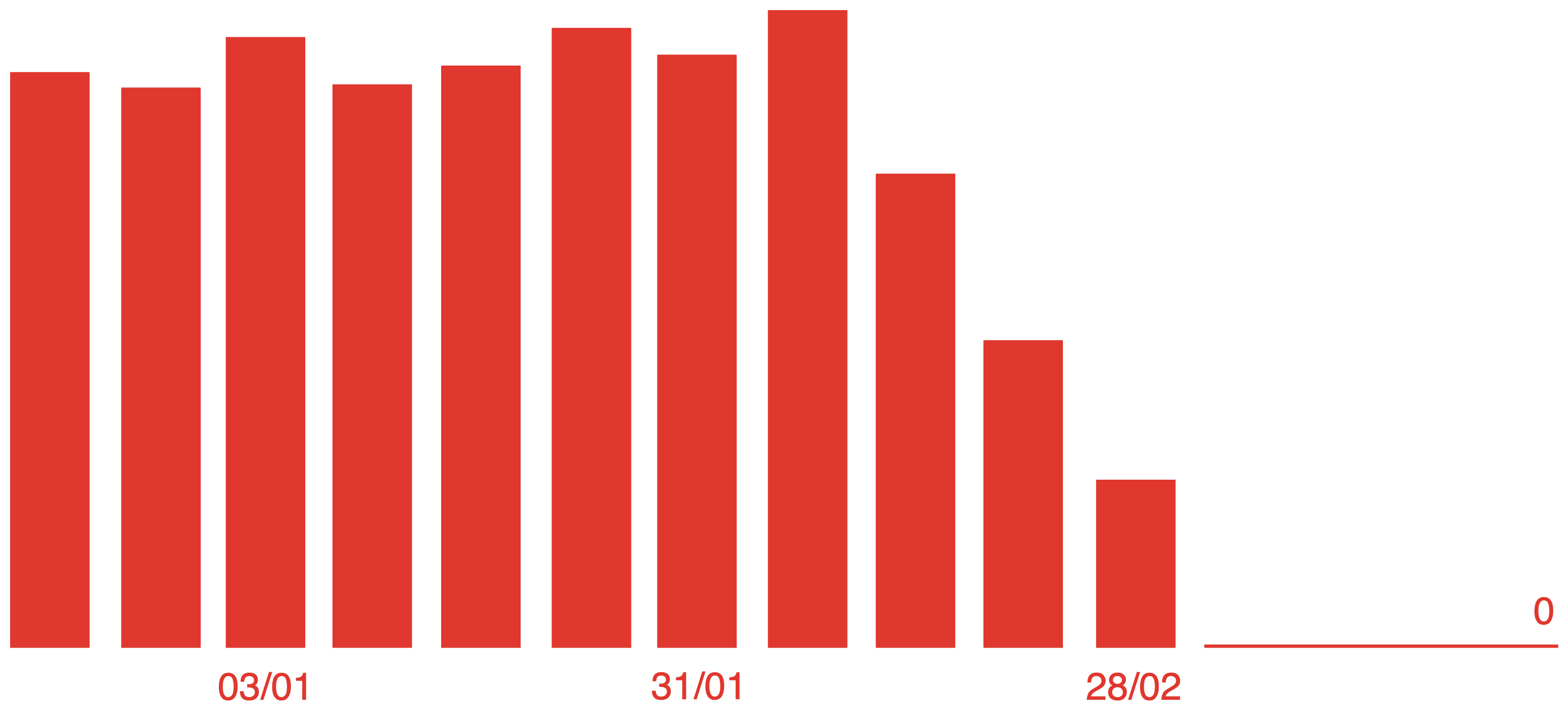
In December 2022, my team had a backlog of 15 support tickets and about 4 new ones per week. The oldest ticket was more than 6 months old. We would fix them, of course, but we prioritized them against other features. We started doing Dantotsu radical quality at that time.
Every day (except on Mondays), we have a radical quality meeting with the AutoRABIT CEO, the VPs of engineering, the QA manager, the engineering team leads, and select people from those teams. On each day, my team discusses the current state of our quality (backlog and new issues) and one person presents a finished PDCA. The total duration of this meeting is half an hour, so we’d better be prepared. This quality meeting encourages reflection and understanding of the issues and does not seek to blame. Problems will happen all the time so it’s best to welcome them as interesting puzzles.
With this perspective, critical issues are less likely to happen. When they do, we are able to think more sharply because we’ve trained every day. Every month, we analyze our last PDCAs and attempt to find our weak points. One of them, it turned out, was that my team and the Service Reliability Operators team had misconceptions about how and where our code should be deployed. It was hard, but we reinforced our standards and an entire class of problems disappeared.
The "random analysis failures" puzzle nagged us for a while. Together with software engineer Sai Anurag, we ran multiple experiments and found ways to reinforce job status reporting. We managed to get rid of those failures entirely by reviewing our software architecture. It turned out that we were over-relying on a brittle webhook mechanism, as they were not a critical part of the job status update. We worked to decouple them, keeping job status reporting in our backend data flows (so they would not depend on the Internet), and using those webhooks for logging purposes, which were their original design intent. Ultimately we all enjoyed this because we gave a lot of thought to the ecosystem surrounding our code, and the engineers in my team learned a ton. We know that we've got a remaining fragility in our DNS system and plan on exploring this more in the coming weeks.
Because of this, we progressively had fewer customer support tickets coming in and we found the time and courage to learn about harder problems that had been teasing us for a while. Finally, in March 2023, our count of open tickets went to 0 and stayed there for 2 weeks.
I’m grateful that we got the opportunity to really focus and think about our customers’ problems, which would not have been possible without the leap of faith of our CEO, Meredith Bell. My entire team is also pleased with the results and is starting to feel more confident about the work that is getting delivered. Everyone participates in PDCA to deeply understand problems, which is the starting point of radical quality. Dantotsu is not over for us, we’re just getting started. We categorize our problems using a "seriosity" rating which counts the number of handovers between their occurrence and their detection. We may have got our count of “type D” (3 handovers) customer problems down to 0, we still have too many “type B” (1 handover) problems caught by our quality team before they reach production, and too many “type A” (0 handovers–found inside the team) problems that hinder our development process. I am looking forward to all the things we’ll learn in the near future.